1. Data Standardization Manual for CogGym
This document outlines the standardized file structure and JSON schemas required for submitting a dataset to the CogGym benchmark. The goal is to create a consistent, machine-readable format for diverse cognitive science experiments.
1.1. EML - Experiment Markup Language
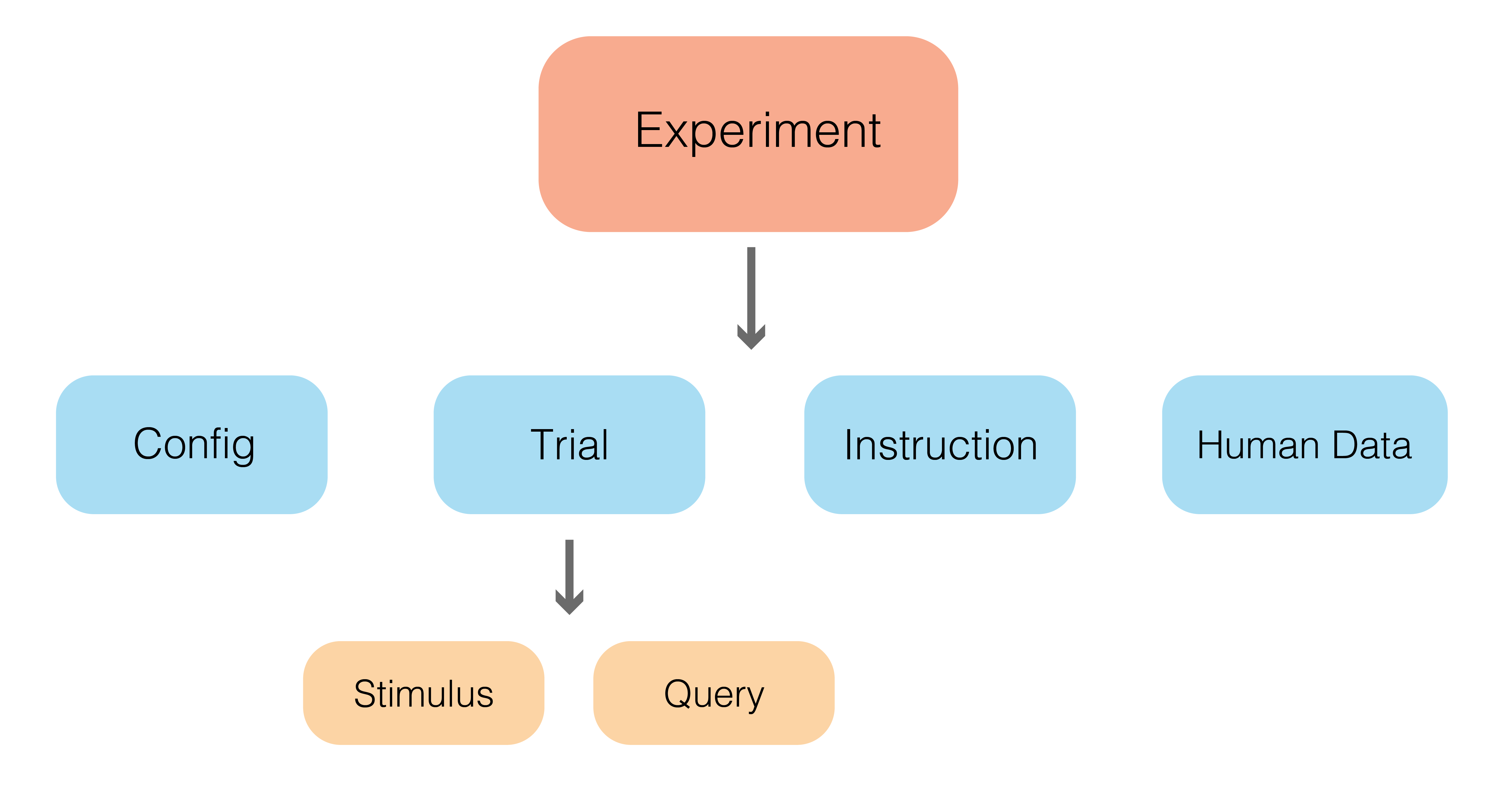
EML (Experiment Markup Language) is a JSON-based markup language for describing the critical components of an online experiment. EML specifies:
- Configuration (study metadata and experiment flow)
- Trials (what participants see (stimuli) and respond to (queries))
- Instructions (pre-task guidance, practice, and comprehension checks)
- Human Data (individual and aggregated response formats)
By adhering to EML, experiments become portable, reproducible, and easy to render consistently across platforms.
This guide is structured to follow the logical components of an experiment:
- 2. Config Schema (config.json): How to define the experiment's metadata and the flow of trials.
- 3. Trial Schema (trial.jsonl): How to define what a participant sees (stimuli) and is asked (queries).
- 4. Instruction Schema (instruction.jsonl): How to define the instructions and quizzes shown before the experiment.
- 5. Human Data Schema: How to format the anonymized participant responses.
1.2. Directory Structure
Each dataset must be contained within a single directory, named according to the convention below. A study may have multiple experiments, each in its own subdirectory (exp1, exp2, etc.). If there is only one experiment, it should still be placed in an exp1 subdirectory. Every study directory must include a top-level README.md, and every experiment subdirectory must include its own README.md summarizing the experiment-specific contents.
[DatasetName]/
├── README.md
├── exp1/ (or exp1, exp2, exp3, etc. if multiple experiments)
│ ├── README.md
│ ├── trial.jsonl
│ ├── config.json
│ ├── instruction.jsonl
│ ├── human_data_ind.json
│ ├── human_data_mean.json
│ └── assets/
│ ├── stimulus_image_01.png
│ ├── stimulus_video_01.mp4
│ └── ...
├── exp2/ (optional, if study has multiple experiments)
│ ├── README.md
│ ├── trial.jsonl
│ ├── config.json
│ └── ...
1.3. Naming Convention (Folder Name)
The name of the root folder ([DatasetName]) should follow the following convention: [AuthorLastName][Year][FirstNonArticleWordOfTitle]
- [AuthorLastName]: The last name of the first author.
- [Year]: The four-digit publication year.
- [FirstNonArticleWordOfTitle]: The first word of the paper's title that is not an article (e.g., "A", "An", "The").
Examples:
- Paper: "Understanding Epistemic Language with a Language-augmented Bayesian Theory of Mind" (Ying et al., 2025)
- Paper: "A Minimal Theory of Mind for Social Agents" (Rabinowitz et al., 2018)
- Folder Structure:
Rabinowitz2018Minimal/with at minimum anexp1/subdirectory
1.4. File Summary
Each experiment subdirectory (exp1, exp2, etc.) must contain the following files:
trial.jsonl: Definitions for all stimuli and experimental trials.config.json: Core configuration, metadata, and experiment flow for the experiment.instruction.jsonl: Defines the pre-experiment instruction and quiz steps.human_data_ind.json/human_data_mean.json: Anonymized human subject data.README.md: Required narrative summary describing the experiment, linking to relevant documentation, and noting unique considerations.assets/(Optional Folder): This folder is required if and only if the experiment uses non-textual stimuli (e.g., images, audio, video).
1.5. File Format Specifications
The following sections detail the required structure for each file. Please refer to them to ensure your files are compliant.
1.5.1. Config Schema (config.json)
Provides high-level metadata about the experiment (name, description, DOI) and controls the experiment flow (e.g., block order, randomization). See Section 2 for the full specification.
1.5.2. Trial Schema (trial.jsonl)
Defines individual experimental trials, including stimuli (images, videos) and the questions asked (sliders, multiple-choice, etc.). See Section 3 for the full specification.
1.5.3. Instruction Schema (instruction.jsonl)
Defines the sequence of instruction pages, practice trials, and comprehension quizzes presented to the participant before the main task. See Section 4 for the full specification.
1.5.4. Human Data Schema
Specifies the format for both individual participant data (human_data_ind.json) and aggregated mean data (human_data_mean.json). See Section 5 for the full specification.